
เรื่อง เทคนิคการเขียนโปรแกรม Map/Reduce สำหรับการประมวลผลข้อมูลขนาดใหญ่ (ตอนที่ 3)
เทคนิควิธี Continuous Map/Reduce
Continuous Map/Reduce เป็นเทคนิควิธีการเขียนโปรแกรมให้กับฟังก์ชัน Map และฟังก์ชัน Reduce ให้เกิดกระบวนการ Map/Reduce อย่างต่อเนื่อง (Continuous) มีจุดประสงค์เพื่อเพิ่มประสิทธิภาพในการประมวลผลข้อมูลขนาดใหญ่ให้เป็นไปอย่างรวดเร็ว (Speed Up) [1, 2]
แนวความคิดการทำ Continuous Map/Reduce เกิดจากกระบวนการทำ Map/Reduce โดยทั่วไปจะเหมาะสมในการทำ Map/Reduce กับข้อมูลที่มีลักษณะคงที่ (Static Data) หรือข้อมูลที่มีการเปลี่ยนแปลงช้า แต่ในความเป็นจริงข้อมูลที่ต้องในปัจจุบันก็มีลักษณะข้อมูลที่มีการเปลี่ยนแปลง Update อยู่เสมอ (Dynamic Data) เช่นกัน ถ้ากระบวนการทำ Map/Reduce ต้องประมวลผลใหม่ทุกครั้งเมื่อมีการเรียกใช้ ย่อมทำให้เสียเวลาและเกิดความล่าช้าในการประมวลผลกับข้อมูลขนาดใหญ่ จึงเป็นที่มาของเทคนิควิธีการทำ Continuous Map/Reduce ซึ่งเป็นกระบวนการทำ Map/Reduce อย่างต่อเนื่องให้กับข้อมูลทุกครั้ง เมื่อข้อมูลมีการเปลี่ยนแปลงหรือถูก Update ให้เป็นปัจจุบันอย่างต่อเนื่องกันไป
• Variety หมายถึง ข้อมูลมีหลากหลายรูปแบบทั้งที่มีโครงสร้างและไม่มีโครงสร้าง ซึ่งอาจจะอยู่ในรูปของ RDBMS, text, XML, JSON หรือ Image
การตื่นตัวของ Big data ทำให้เกิดการพัฒนาวิธีการหรือเทคโนโลยีใหม่ ๆ เพื่อนำมาใช้จัดการกับข้อมูลจำนวนมากเหล่านี้ ซึ่งหนึ่งในวิธีการเหล่านั้นคือการทำ Map/Reduce Framework ที่เป็นวิธีการเขียนโปรแกรมแบบหนึ่งที่ใช้ในการแก้ปัญหาการประมวลข้อมูลขนาดใหญ่ ตัวอย่างในปัจจุบันวิธีการทำ Map/Reduce ถูกนำไปใช้ในองค์กรและผู้ให้บริการเว็บไซต์ เช่น Facebook และ Twitter และยังถูกนำไปใช้ในการประมวลผลในงานด้าน ๆ อื่น เช่น ในการจำแนกประเภทข้อมูลที่มีลักษณะเป็นข้อความจำนวนมาก ๆ [1] นำไปใช้แก้ไขปัญหาขนาดของฐานข้อมูลในปัจจุบันที่มีอัตราการเติบโตเพิ่มขึ้น [2, 3] และนำไปประยุกต์ใช้ร่วมกับเทคนิคอื่น ๆ เช่น การทำ Map/Reduce ที่นำมาใช้ร่วมกับการทำโครงข่ายประสาทเทียบ (Neural Network) ในระบบการเรียกค้นคืนส่วนข้อมูลภาพ (Content Based Image Retrieval) [4]
โดยปกติทั่วไปการกำหนดการทำงานภายใน Map/Reduce Framework เกิดจากความต้องการของผู้ใช้หรือผู้เขียนโปรแกรมกำหนดการทำงานภายในฟังก์ชัน Map และฟังก์ชัน Reduce ประมวลผลบนข้อมูลตามที่ต้องการ ซึ่งการเขียนโปรแกรมลักษณะนี้ต้องเกิดจากประสบการณ์การศึกษาเทคนิควิธีการต่าง ๆ ที่ใช้กำหนดการทำงานภายในฟังก์ชัน Map/Reduce
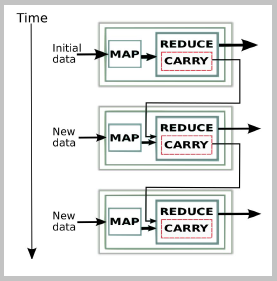
รูปที่ 1 Execution Flow of Continuous Job [16]
 สำหรับแนวคิดของ Continuous Map/Reduce อธิบายในรูปที่ 1 ซึ่งลักษณะขั้นตอนการทำงานเริ่มจากการรับข้อมูลอินพุตแล้วนำมาทำการ Map/Reduce ตามปกติ โดยมีการกำหนด Carry Method ให้เก็บค่าข้อมูล output (Key, Value) เพื่อใช้ในการทำ Map/Reduce ในเวลาทัดไป และเมื่อข้อมูลมีการ Update ข้อมูลดังกล่าวก็จะถูกทำ Map/Reduce โดยมีการใช้ Carried data (output (key, value)) จากขั้นตอนการ Map/Reduce ก่อนหน้า จะถูกเพิ่มเป็นข้อมูล Input ของ Reduce ในการดำเนินการในครั้งต่อไป (Next Execution) และเมื่อมี New data เข้ามาก็จะเริ่มการทำ Map/Reduce ในครั้งต่อไป ในลักษณะการทำงานแบบต่อเนื่องกันไป ข้อดีก็การ Map/Reduce อย่างต่อเนื่องนี้ คือ ไม่จำเป็นต้องดำเนินการซ้ำกับข้อมูลอินพุตทั้งหมดในการทำ Map/Reduce ในแต่ละรอบการทำงาน และยังช่วยรักษาความถูกต้องของข้อมูลเอาต์พุตที่มีอยู่ก่อนหน้าและข้อมูลเอาต์พุตที่กำลังประมวลผลใหม่
สำหรับแนวคิดของ Continuous Map/Reduce อธิบายในรูปที่ 1 ซึ่งลักษณะขั้นตอนการทำงานเริ่มจากการรับข้อมูลอินพุตแล้วนำมาทำการ Map/Reduce ตามปกติ โดยมีการกำหนด Carry Method ให้เก็บค่าข้อมูล output (Key, Value) เพื่อใช้ในการทำ Map/Reduce ในเวลาทัดไป และเมื่อข้อมูลมีการ Update ข้อมูลดังกล่าวก็จะถูกทำ Map/Reduce โดยมีการใช้ Carried data (output (key, value)) จากขั้นตอนการ Map/Reduce ก่อนหน้า จะถูกเพิ่มเป็นข้อมูล Input ของ Reduce ในการดำเนินการในครั้งต่อไป (Next Execution) และเมื่อมี New data เข้ามาก็จะเริ่มการทำ Map/Reduce ในครั้งต่อไป ในลักษณะการทำงานแบบต่อเนื่องกันไป ข้อดีก็การ Map/Reduce อย่างต่อเนื่องนี้ คือ ไม่จำเป็นต้องดำเนินการซ้ำกับข้อมูลอินพุตทั้งหมดในการทำ Map/Reduce ในแต่ละรอบการทำงาน และยังช่วยรักษาความถูกต้องของข้อมูลเอาต์พุตที่มีอยู่ก่อนหน้าและข้อมูลเอาต์พุตที่กำลังประมวลผลใหม่
สำหรับการทดลองประสิทธิภาพ Continuous Map/Reduce ถูกนำไป Implement เพิ่มเติมขยายในส่วนการทำ Map/Reduce เดิมในกรอบการทำงานของ Hadoop โดยการเพิ่มหน่วย Continuous Job Tracker ทำหน้าที่รับผิดชอบการแบ่งงานและจัดตารางการทำงานในลักษณะการทำงานอย่างต่อเนื่อง เพื่อส่งให้ Job Tracker นำไปประมวลผลบน Cluster โดยมี Continuous Job Tracker ค่อยควบคุมการรับข้อมูลอินพุตที่มีการ Update ตลอดเวลา ส่วน Continuous Name Node ทำหน้าที่รับผิดชอบติดตามการทำงานอย่างต่อเนื่อง หากมีงานที่ต้องทำการ Map/Reduce จะทำหน้าที่ค่อยตรวจสอบเส้นทางในการจัดเก็บและประมวลผลข้อมูลใหม่บน Data Nodes ต่าง ๆ
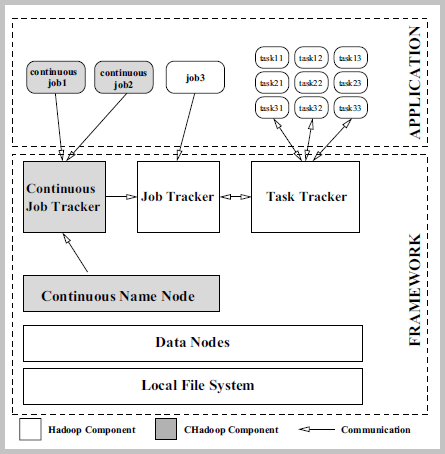
รูปที่ 2 Continuous Map/Reduce in Hadoop [1]
1. Trong-Tuan, V. and F. Huet. A Lightweight Continuous Jobs Mechanism for MapReduce Frameworks. in Cluster, Cloud and Grid Computing (CCGrid), 2013 13th IEEE/ACM International Symposium on. 2013.
2. Chen, Q. and M. Hsu, Data-Continuous SQL Process Model, in Proceedings of the OTM 2008 Confederated International Conferences, CoopIS, DOA, GADA, IS, and ODBASE 2008. Part I on On the Move to Meaningful Internet Systems:. 2008, Springer-Verlag: Monterrey, Mexico. p. 175-192.
ดร. สุวรรณี ธูปจีน
อังคารที่ 23 มกราคม 2561
“ขอสงวนสิทธิ์ ข้อมูล เนื้อหา บทความ และรูปภาพ (ในส่วนที่ทำขึ้นเอง) ทั้งหมดที่ปรากฎอยู่ในเว็บไซต์ ห้ามมิให้บุคคลใด คัดลอก หรือ ทำสำเนา หรือ ดัดแปลง ข้อความหรือบทความใดๆ ของเว็บไซต์ หากผู้ใดละเมิด ไม่ว่าการลอกเลียน หรือนำส่วนหนึ่งส่วนใดของบทความนี้ไปใช้ ดัดแปลง เพื่อการพาณิชย์โดยไม่ได้รับอนุญาตเป็นลายลักษณ์อักษร จะถูกดำเนินคดี ตามที่กฎหมายบัญญัติไว้สูงสุด ในกรณีต้องการอ้างอิงเพื่อการศึกษา กรุณาให้เครดิตโดยอ้างอิงถึงผู้เรียบเรียงและบริษัทเจ้าของเว็บไซด์ด้วย”