
เรื่อง เทคนิคการเขียนโปรแกรม Map/Reduce สำหรับการประมวลผลข้อมูลขนาดใหญ่ (ตอนที่ 4)
เทคนิควิธี Overlapping Map/Reduce
เทคนิควิธีการทำ Overlapping Map/Reduce [1] เป็นการเขียนโปรแกรมกำหนดการทำงานให้กับฟังก์ชัน Map และฟังก์ชัน Reduce ให้เกิดประสิทธิภาพในการประมวลผลข้อมูลขนาดใหญ่เป็นไปได้อย่างรวดเร็ว (Speed up) ซึ่งเกิดจากโดยทั่วไปการเขียนฟังก์ชันให้กับ Map/Reduce ให้เริ่มทำงานนั้น ฟังก์ชัน Reduce จะเริ่มทำงานได้ก็ต่อเมื่อฟังก์ชัน Map ถูกทำให้เสร็จก่อน แต่ถ้าเกิดมีเหตุการณ์ที่อาจส่งผลต่อการประมวลในฟังก์ชัน Map ทำให้ฟังก์ชันเกิดการทำงานล่าช้า ซึ่งนั่นคือจะส่งผลต่อเวลาที่ใช้ในการประมวลผลทั้งระบบไปด้วย ซึ่งอาจเกิดเหตุการณ์ส่งผลกระทบดังนี้
Dependence: ในขั้นตอนการทำ Reducers จะไม่สามารถเริ่มการทำงานก่อนได้เพราะต้องรอให้ขั้นตอนในการทำ Mappers ให้กับข้อมูลเสร็จสิ้นก่อนถึงจะสามารถส่งต่อให้ Reducers ทำงานต่อได้ ซึ่งจะมีผลต่อการทำงานในภาพรวมทั้งระบบ หากขั้นตอนในการทำ Mappers ล่าช้าก็จะส่งผลให้ Reducers ทั้งหมดต้องรอไปด้วย
Disk access (multiple read/write): ในระหว่างการกำหนดค่าคู่ Key/Value ในขั้นตอนการทำ Mapping จะต้องทำการ writing disk access และจะต้องทำการ Reading disk access ในขั้นตอนการทำ Reducing อีกครั้ง ซึ่งจะส่งผลต่อการปฏิบัติงานของระบบ โดยเฉพาะอย่างยิ่งถ้ามีการประมวลผลออกมาในอัตราที่สูงจะมีผลต่อการทำ Read/Write ในระบบ
All-to-All communication: ในขั้นตอนการทำ Shuffling จะทำให้เกิด Communication ระหว่างเครื่องเป็นจำนวนมาก ซึ่งจะส่งผลต่อเวลาที่ใช้ในการทำงานทั้งระบบ
และในการแก้ปัญหาดังกล่าวจึงได้กำหนดวิธีการโดยใช้รูปแบบการเขียนโปรแกรม Message Passing Interface (MPI) ให้กับเทคนิค Overlapping Map/Reduce ที่มีการทำ Mapping, Shuffling, Merging และ Reducing เหมือนการทำ Map/Reduce ทั่วไป [2] แต่ได้เพิ่มรูปแบบการเขียนโปรแกรมแบบขนานให้กับฟังก์ชัน Map/Reduce โดยได้นำเสนอความคิดของการทำงานทับซ้อนกัน (Overlap) ระหว่างฟังก์ชัน Map และฟังก์ชัน Reduce ซึ่งส่งผลให้เกิดการประมวลผลที่เร็วขึ้น (Speed up)
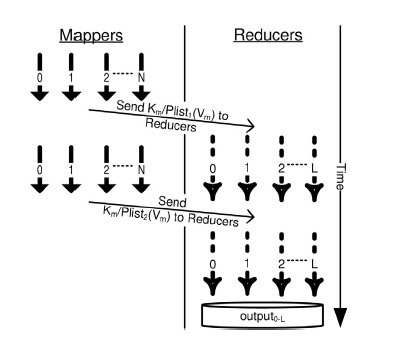
รูปที่ 1 MRO-MPI: The mappers and reducers work in parallel and partial data is sent in a pipeline fashion [1]
จากรูปที่ 1 แสดงกระบวนการการทำงานของโมเดล MRO-MPI โดยการส่งข้อมูลบางส่วนในระหว่างการทำ Mappers ให้กับ Reducers ทำงานในลักษณะคู่ขนาด โดยที่ Reducers จะทำงานกับข้อมูลในส่วนที่ถูกส่งมากก่อนและรอข้อมูลทั้งหมดที่ได้จากการทำ Mappers เสร็จสิ้นลง ด้วยรูปแบบโมเดลนี้จึงต้องมีการกำหนดกฎ Multiple read/write เนื่องจากถ้าในระหว่างการทำ Mappers มีการส่งข้อมูลบางส่วนโดยตรงกับ Reducers ก็ไม่มีความจำเป็นในการบันทึกข้อมูลระว่างทางในการทำ Mappers ดังนั้นในขั้นตอนการทำ Shuffling จะถูกรวบเข้ากับขั้นตอนในการทำ Mappers แทนที่จะทำงานแยกกัน
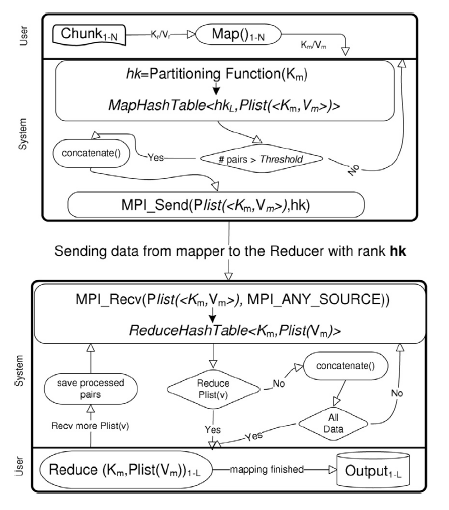
รูปที่ 2 Overlapping Map/Reduce Technical Detail [1]
เทคนิควิธีการทำ Overlapping Map/Reduce ยังคงความเรียบง่ายสำหรับรูปแบบการเขียนโปรแกรมให้กับฟังก์ชัน Map และฟังก์ชัน Reduce แต่สามารถเพิ่มความเร็วได้เมื่อเปรียบเทียบกับการทำงานของ Map/Reduce ทั่วไปใน Hadoop เพราะมีการแยกการทำงานของทั้งสองฟังก์ชันให้สามารถทำงานซ้อนทับกันได้ (Overlapping) ทำให้ Reducers สามารถทำงานได้โดยไม่ต้องรอให้ฟังก์ชัน Mappers ทำงานเสร็จก่อน จึงทำให้สามารถทำงานได้พร้อมกันซึ่งส่งผลให้ลดเวลาในการทำงานและให้ความเร็วที่ดีขึ้น
1. Mohamed, H. and S. Marchand-Maillet, MRO-MPI: MapReduce overlapping using MPI and an optimized data exchange policy. Parallel Computing, 2013. 39(12): p. 851-866.
2. Plimpton, S.J. and K.D. Devine, MapReduce in MPI for large-scale graph algorithms. Parallel Computing, 2011. 37(9): p. 610-632.
ดร. สุวรรณี ธูปจีน
อังคารที่ 30 มกราคม 2561
“ขอสงวนสิทธิ์ ข้อมูล เนื้อหา บทความ และรูปภาพ (ในส่วนที่ทำขึ้นเอง) ทั้งหมดที่ปรากฎอยู่ในเว็บไซต์ ห้ามมิให้บุคคลใด คัดลอก หรือ ทำสำเนา หรือ ดัดแปลง ข้อความหรือบทความใดๆ ของเว็บไซต์ หากผู้ใดละเมิด ไม่ว่าการลอกเลียน หรือนำส่วนหนึ่งส่วนใดของบทความนี้ไปใช้ ดัดแปลง เพื่อการพาณิชย์โดยไม่ได้รับอนุญาตเป็นลายลักษณ์อักษร จะถูกดำเนินคดี ตามที่กฎหมายบัญญัติไว้สูงสุด ในกรณีต้องการอ้างอิงเพื่อการศึกษา กรุณาให้เครดิตโดยอ้างอิงถึงผู้เรียบเรียงและบริษัทเจ้าของเว็บไซด์ด้วย”